I’ve recently been talking with some executives who bemoan the risk management in their organisations. They don’t trust the risks as they are presented and worry about putting their finite resources of money and time in the wrong places because of it. They worry that as soon as the analysts are uncertain they increase the likelihood or harm (likely following a variant of the precautionary principle, when in doubt assume the worst) which leads to time and resources used inefficiently or wasted.
There is also the opposite case where a risk is seen as so rare and unusual that it is judged that it must rarely happen and the likelihood of what could incredibly damaging or even existential risks are minimised to such a degree that they are not even considered in broader resilience activities. At best they are assumed to be ‘black swans’ that could never have been predicted in advance. The difficulty with this is that someone predicted it as a possibility and considered it rare, it’s not a classic ‘black swan’ that is predictable only in hindsight, instead it is hugely damaging risk that was mis-characterised. Often the lack of data on previous risk events lies at the root of this issue.
If an existential risk that is predicted never to happen appears on a risk register you must ask what is the strength of the knowledge that prediction is based on, if the strength of knowledge is poor then the reliability of the prediction is poor and it is worth spending some time and money improving that strength of knowledge.
That there is a lot of implicit knowledge and assumptions involved in our common risk assessment processes that leads to less effective decision making and we often present our assessments of likelihood and impact divorced from the underlying data and assumptions that lead to our estimation of the risk. That is a mistake.
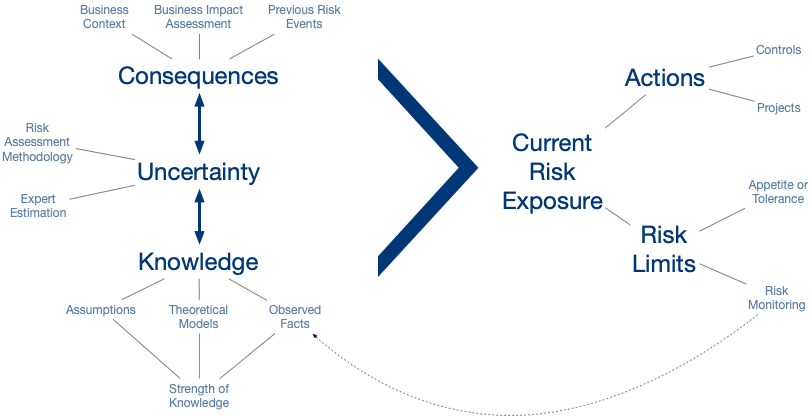
A risk is, as I have said earlier, at its simplest an event and a consequence. In order to estimate that risk we consider how probable we believe that event to be over a set time period and we consider what the range of consequences may be if that risk occurs. Especially in Information Security we have a high level of uncertainty about probability and consequence which makes understanding the knowledge we base our estimates of that uncertainty absolutely critical.
We can improve expert estimation (There is an extensive introduction to this here) and we can also look at and understand the strength of the knowledge we are basing those estimates on which could be working assumptions we have made based on our experience (Estall & Purdy make a compelling case that assumptions must be explicitly included and recorded when making decisions under uncertainty in their excellent book), theoretical models of how the risk factors interact we have developed or our direct observation of facts.
The strength of this knowledge must not only be understood but it needs to be presented to decision makers alongside the uncertainty and consequences (Likelihood and Impact of you prefer) in order for them to make informed judgements about the reliability of the risk analysis being presented. It is difficult for a risk analysis to present the weakness of their knowledge (especially in Information Security where there is great uncertainty and despite being awash with data we see little use of directly observed facts in risk assessments) and it can be hard to deal with executives who are uncomfortable making decisions under such uncertainty but the suppression of uncertainty leads to the sort of distrust that I opened the blog with.
There is also a world of opportunity to start informing risk assessments with reliable directly observed facts or with explicit risk models that have been tested so as to improve the knowledge underpinning our estimation of the risk. I suspect we will see this grow as a discipline within the tech-first businesses that have pioneered compliance-as-code, perhaps we will start seeing risk-as-code emerging. That would be something worth exploring.
I prefer “suppression of uncertainty leads to distrust” to my variant which is: “Dumbing risk down loses fidelity” but both have a similar negative outcome. Yours puts the onus on the practitioner to ensure they build trust whilst mine puts the onus on the practitioner to disclose the right facts. I suspect we’re looking at the same coin from opposite sides.
This is a great article. Like it loads.