I was recently working with a firm to develop their Security Operations Centre (SOC) from a good but limited capability to a mature enterprise capability. While working through the maturity assessment, formalising their requirements and developing a roadmap we needed to consider a variety of delivery model characteristics. To draw out some of the key characteristics we needed to consider the organisation itself but also the state of SOC components.
To dig into this we developed a Wardley map mapping the value chain and evolution of SOC components. Wardley maps look complicated but are effectively a tool for discussion in front of a white board to identify dependencies and the maturity of components and services. (Click on the diagram for a full size version).
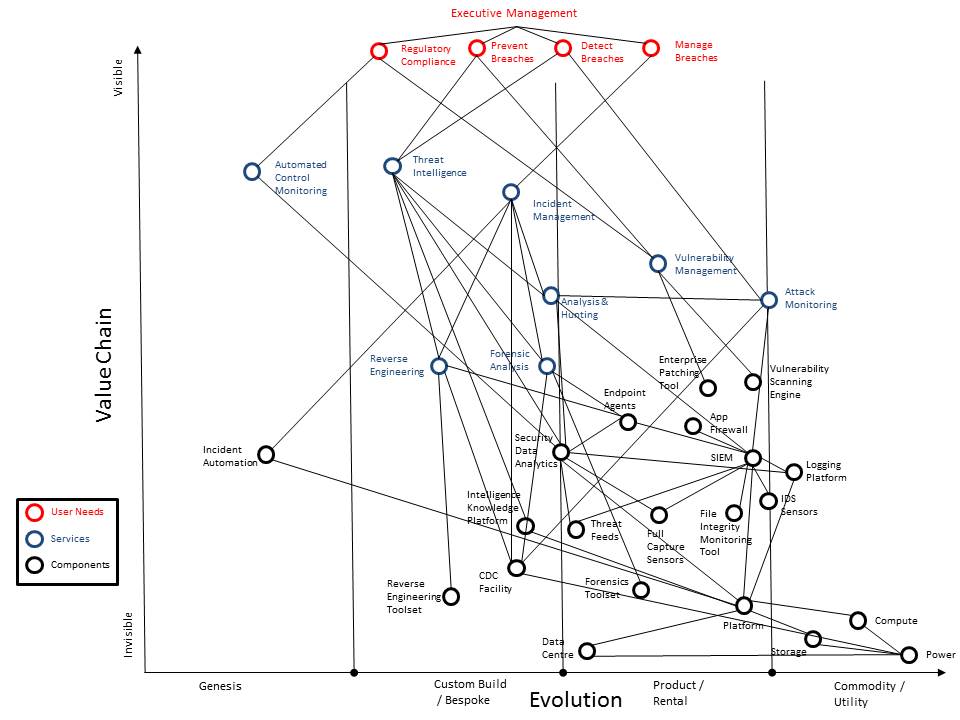
The services in this particular map were defined as:
| Service Name | Service Description |
| Vulnerability Management |
The Vulnerability Management service will identify and scan devices and systems connected to the network for security vulnerabilities and will report on these to stakeholders on a regular schedule and on-demand. |
| Threat Intelligence |
The Threat Intelligence service will identify, characterize and track cyber adversaries, will generate actionable intelligence from external feeds and internal data sources as well as engage with external peers to collaborate and share information. |
| Automated Control Monitoring |
The Automated Control Monitoring service will use the SOC Monitoring Data to track the effectiveness and performance of security controls both for stakeholders that operate those controls and for audit purposes. |
| Attack Monitoring |
The Attack Monitoring service will provide level 1 and level 2 analysis of SOC monitoring data to triage security events, identify security attacks and verify security incidents. |
| Analysis & Hunting |
The Analysis & Hunting service will provide level 3 analysis of verified security incidents to categorize and prioritize them. Known security incidents will be remediated and higher impact or Unknown security incidents will be escalated to the Incident Management service. When not conducting analysis and remediation support the Analysis & Hunting service will develop Attack Monitoring use case descriptions and conduct pro-active threat hunting. |
| Incident Management |
The Incident Management service will provide investigation and remediation coordination to high impact, known security incidents (that have been handled previously and documented) and unknown security incidents (that have not been previously handled or documented). |
| Forensics | The Forensics service will provide forensic imaging, analysis and evidential storage to the SOC and other investigative teams. |
| Reverse Engineering |
The Reverse Engineering service will provide malware analysis to support Threat Intelligence, Analysis & Hunting, and Incident Management. |
Hopefully the technical components are pretty self explanatory. I’d be interested to hear if people disagree with where we ended up, please let me know in the comments. I shared this with Simon Wardley himself and he did which was cool and useful:
“On the map itself, the evolution axis is derived from examining ubiquity (how common something is) vs certainty (how well understood something is) – see http://blog.gardeviance.
The point is that for the organisation where we used this it was a useful tool when discussing what could be outsourced because they are well-defined and can be quantitatively managed and what couldn’t currently be outsourced because they are subject to change and development. This allowed us to develop the following map for a potential hybrid delivery model. (Click on the diagram for a full size version).
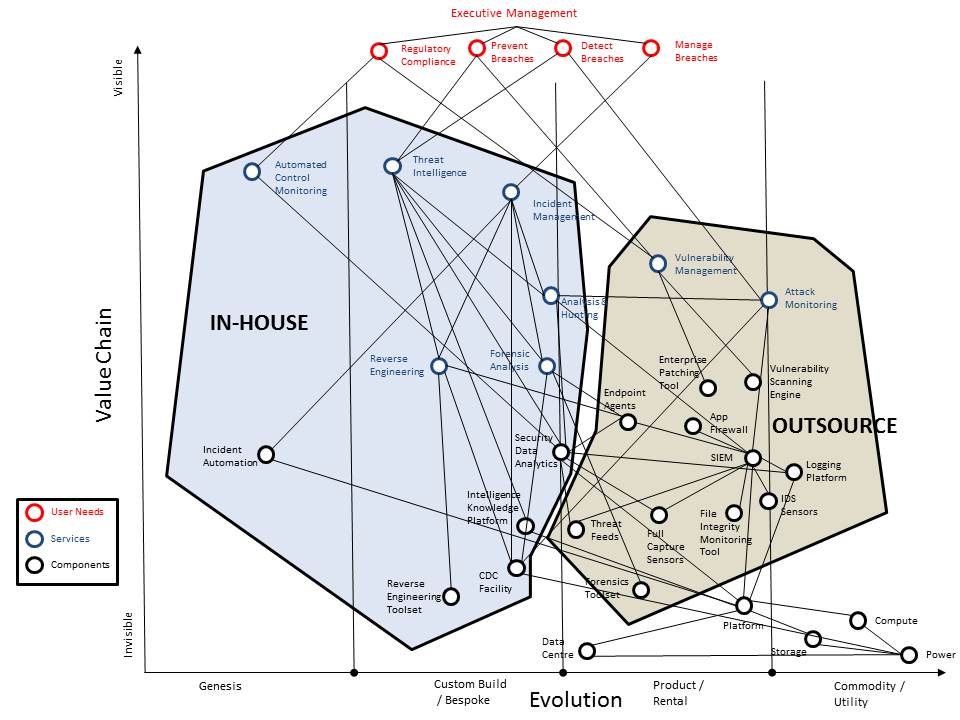
In this case the organisation was so large that there is a very very short list of MSSPs that could scale to meet their requirements so it is likely they will build and operate internally for now but keep a watching brief on the MSSP market as the providers scale their operations over time.
I hope this is a helpful starting point for others considering delivery models for a SOC and with a tip of a hat to Simon Wardley who has developed and made available a very useful approach.

Loved your map, but continue to be struck by the that fact that us security types have not yet got to the formula 1 view of Hybrid. ie KERS A tool that reduces risk AND adds Value!
The Map above was not connected to the goals of the organisation, imagine if we always drew Security Maps that aim to add Value as well as reduce risk.
Your use of the word Hybrid above had me thinking you were going there, my dissapointment prompted this post.
Fancy a beer to discuss further?
I am in principle always available for a discussion over a beer. Drop me an email.
I agree that security has and continues to struggle to add value. KERS is a great example though, I bet that wasn’t a bolt-on control added by a team external to the engineering team with the grudging acceptance of the engineering team. I suspect it was a solution to an external compliance requirement that was fully internalised by the engineering team leading to a ‘hybrid’ control that protected and added value.
We have always had a security engagement problem but we also have an IT engineering problem where many teams have externalised responsibility and accountability for security treating it as an external requirement to be bolted on.
Technical security, when it works and adds value, is something the technology team owns and delivers as a core part of their role (maybe with advice and oversight from specialists elsewhere). I am increasingly of the opinion that security teams have marginal impact on the actual security outcomes and what impact they have is via engagement to the teams that actually deliver the outcomes everyone wants.
See this for some related thoughts http://blog.blackswansecurity.com/2015/04/we-need-to-talk-about-it/
I love this Phil. Basic principles are so often leapfrogged in this capability/demarcation conversation…and the MSSP ubiquity view: great.
What about turning it into a series looking at common vendor/in-house splits and the service level/metrics/incident roles side of things? The ‘we didn’t do it because it wasn’t in the contract’ or ‘….because you didn’t explicitly tell us to/how to’ arguments for security non-delivery/control failure. Folk are basically gagging for a view of what vendors ‘should’ have capability to provide and what it’s reasonable to expect.
This goes a fair way to providing that common level playing field, but a view of common gotchas would be great. Things folk forget to implement to enable integration of MSSP outputs into internal vulnerability/incident/risk management for example. And stuff you need to be careful about with service requirements definition and contact negotiation. Suspect many firms end up paying for lots of things they expected to come included.
Years have passed and now some red teaming capability is essential to have inside SOC. The second thing of importance is centralised detection content management, meaning some storage should be in place (GitLab for instance) and SIEM should be API-managed